
Boost Inference Performance up to 15x on NVIDIA Blackwell Using DFlas…
Source: developer.nvidia.com
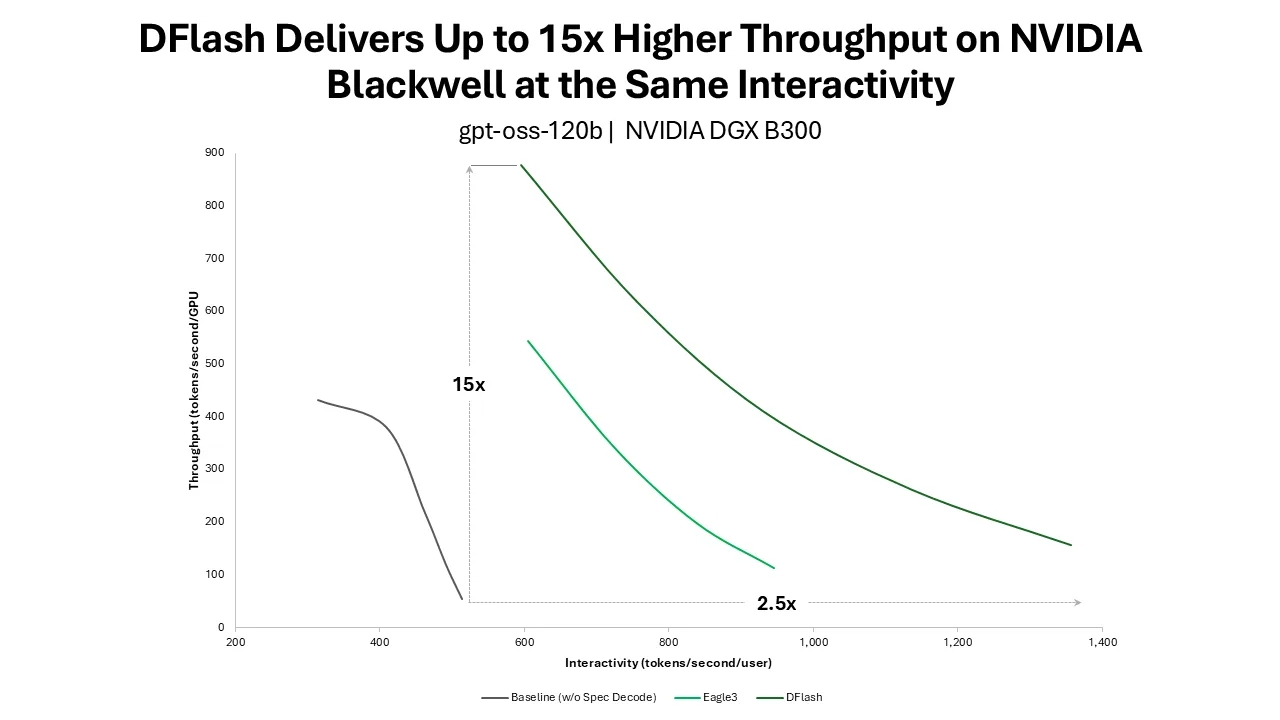
DFlash, an open source lightweight block diffusion model for speculative decoding, boosts inference performance for gpt-oss-120b on NVIDIA Blackwell by up to 15x at the same interactivity level. It nearly doubles interactivity for Llama 3.1 8B at the same concurrency compared with state-of-the-art EAGLE-3 speculative decoding. DFlash uses a block-diffusion drafter to generate an entire block of candidate tokens in a single forward pass, turning sequential drafting into block-parallel GPU work. The research team has released 20 DFlash checkpoints on Hugging Face with recipes for NVIDIA Blackwell and NVIDIA Hopper GPUs. At the high interactivity range of 500-600 tokens/sec per user, DFlash increases throughput on NVIDIA Blackwell by more than 15x compared with autoregressive decoding, and 1.5x higher than EAGLE-3 speculative decoding. At the lowest concurrency point, with batch size 1, DFlash more than doubles interactivity on Blackwell. DFlash is becoming available across NVIDIA GPU inference stacks, including SGLang and vLLM.
SUCKS 0
0
0
Comments
This page shows all existing comments. To add a new comment, open the post in the forum.
No comments yet.