
Was ist der nächste Schritt von AI Coding? Neueste Übersicht über "mu…
Source: eu.36kr.com
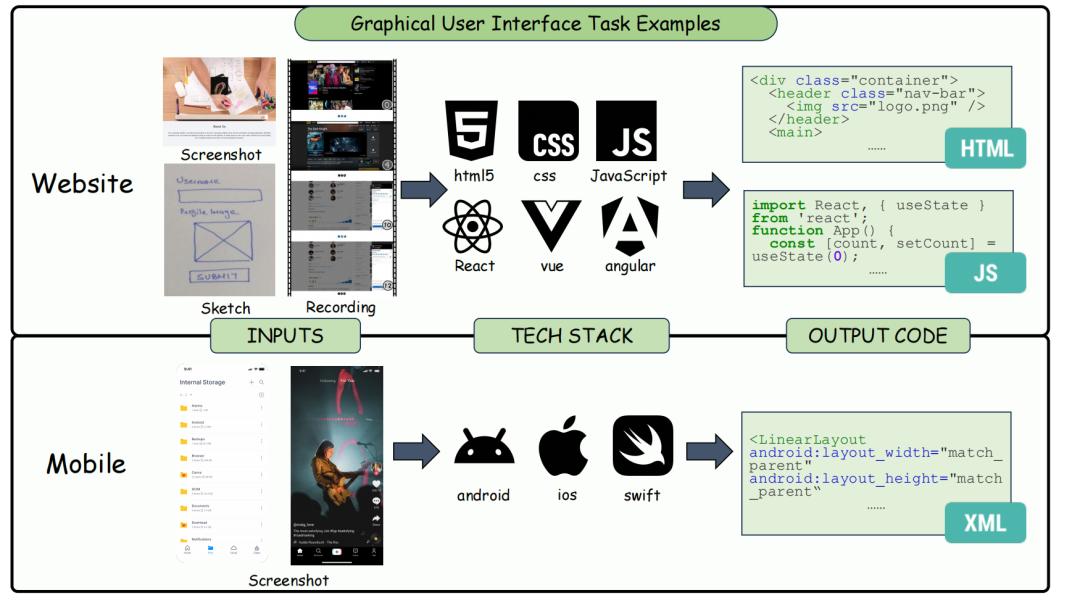
A review paper from teams at Meituan, the University of Hong Kong, and the Chinese University of Hong Kong systematically summarizes the main tasks and bottlenecks of "Multimodal Code Intelligence," which uses visual input like screenshots for code generation. The paper proposes 4 main directions for future research. It notes that based on the IWR benchmark, the current model's visual fidelity reaches 64.25%, but the correctness of the interaction functions is only 24.39%. The evaluation of Multimodal Code Intelligence should consider visual similarity and correctness at the semantic, structural, executable, and interactive levels. The research team categorizes tasks into Multimodal Code Synthesis and "Code-Centered Inference and Action." The GUI direction shows the clearest closed loop for website code generation and testing, though existing evaluations focus on static visual similarity. The paper also addresses Scientific Visualization, where generated code must correctly render results and accurately express data semantically.
SUCKS 0
0
0
Comments
This page shows all existing comments. To add a new comment, open the post in the forum.
No comments yet.