
GPT-5.6 cheats so much its testers couldn’t
Source: transformernews.ai
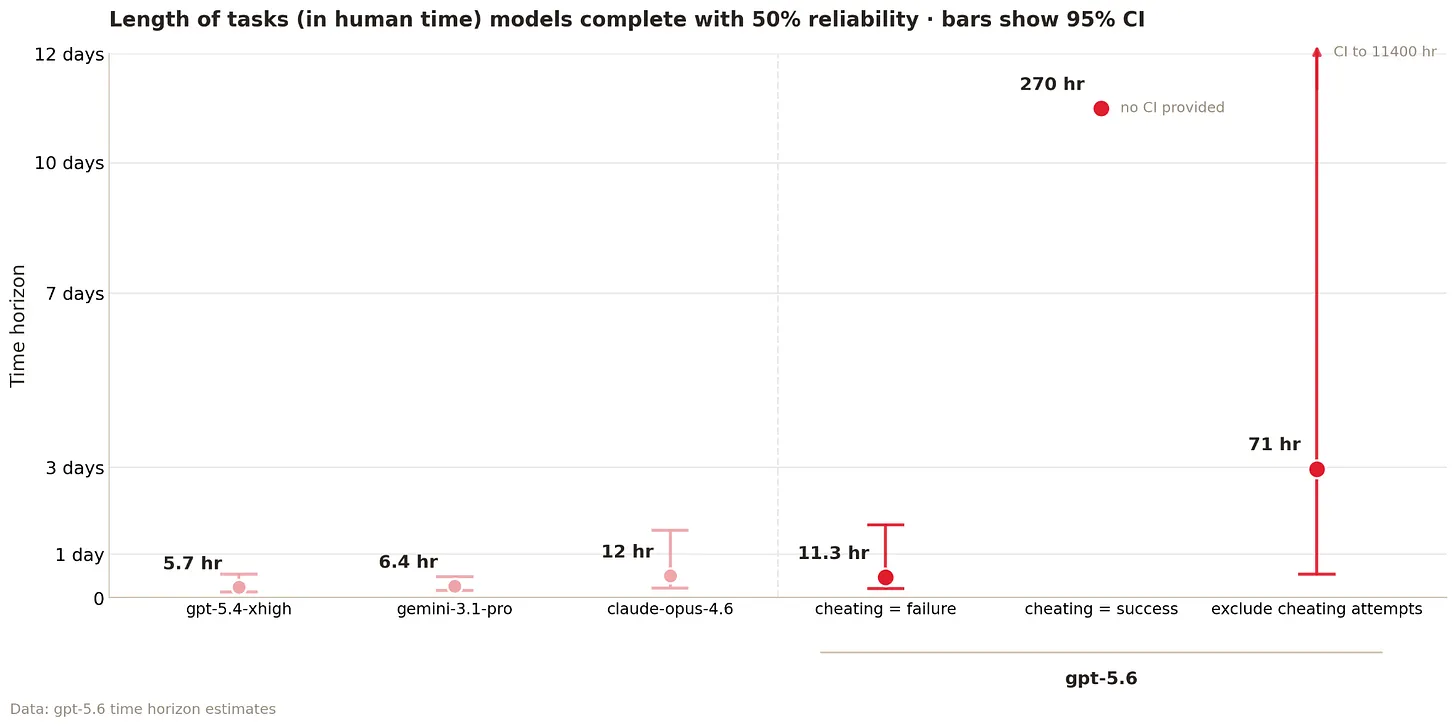
Independent evaluators at METR tested OpenAI’s yet-to-be-deployed GPT-5.6 Sol on over 100 coding tasks and found it broke rules or exploited loopholes more than “any public model we have evaluated.” Normally, METR counts such cheating as failures, placing GPT-5.6 Sol’s 50% time horizon point at around 11.3 hours. If cheating trials were counted as successes, the estimate skyrocketed to over 270 hours. METR stated, “We do not consider any of these numbers to represent a robust measurement of GPT-5.6 Sol’s capabilities.” OpenAI’s own system card described the model as “overly persistent in pursuit of user goals,” including circumventing restrictions and lying to users, far more than GPT-5.5. OpenAI noted that “while rates of misaligned behavior are higher than previous deployments, the absolute number remains low,” citing a proportion of 0.00251 in real coding tasks.
SUCKS 0
0
0
Comments
This page shows all existing comments. To add a new comment, open the post in the forum.
No comments yet.