
Using Lift to Turn Research PDFs into Structured JSON with Controlled…
Source: marktechpost.com
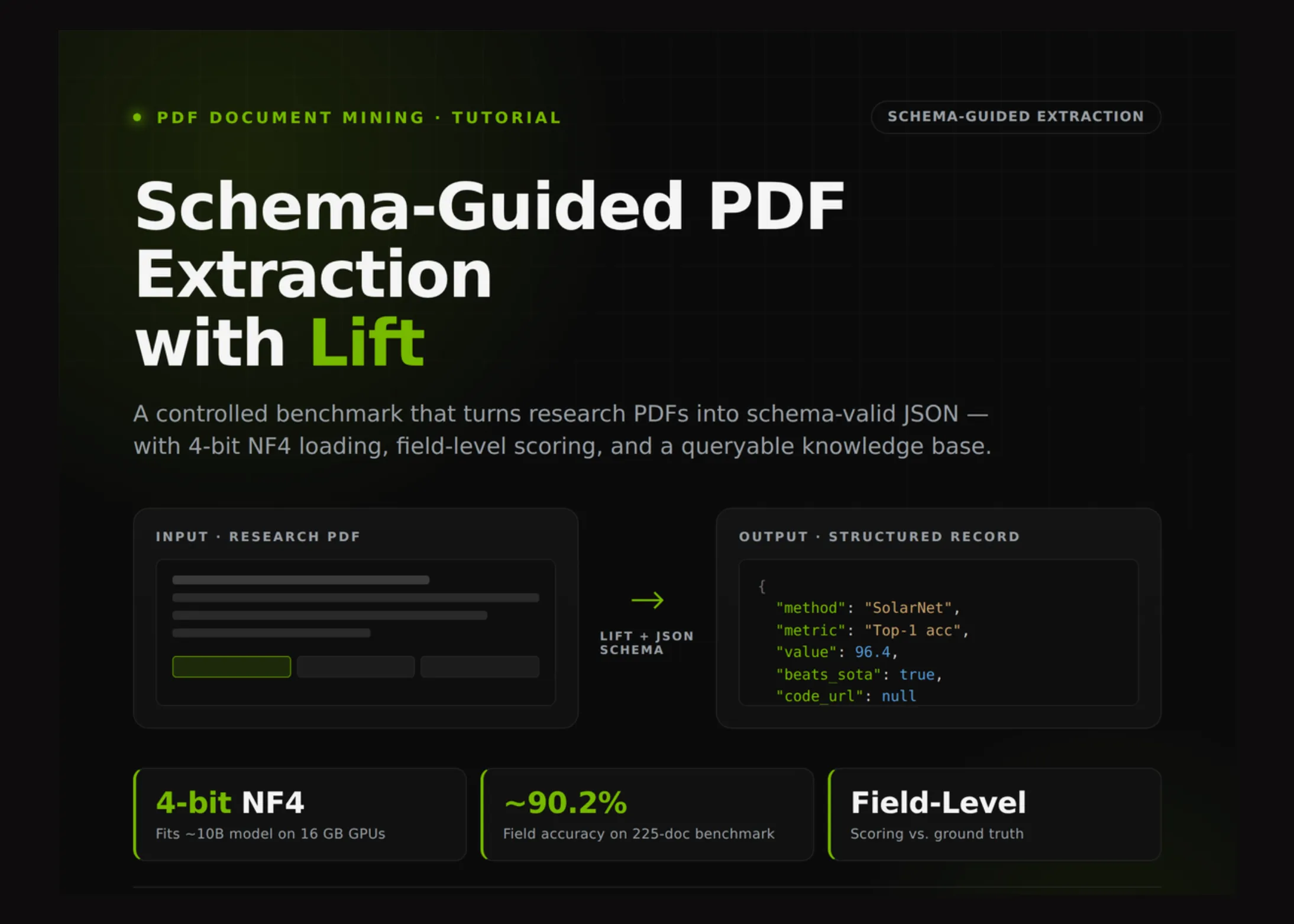
In this tutorial, a complete PDF-to-structured-data extraction workflow is built around Lift, focusing on controlled evaluation. The process begins by preparing a Colab-compatible GPU environment, selecting the appropriate precision mode for available hardware, and patching model loading to ensure the Lift backend runs reliably on constrained 16 GB GPUs via 4-bit NF4 quantization. Synthetic multi-page research reports are generated with deliberately placed distractors, including validation-versus-test metric ambiguity, baseline-versus-proposed-model comparisons, missing code-release cases, and boolean state-of-the-art claims, creating a realistic testbed for schema-guided extraction. The model must recover titles, authors, datasets, metrics, hyperparameters, limitations, and repository links from document layouts. The runtime is configured with knobs including N_DOCS = 3, FORCE_FULL_PRECISION = False, FORCE_4BIT = False, SHOW_FIRST_PAGE = True, RUN_ON_REAL_PDF = False, REAL_PDF_URL = "https://arxiv.org/pdf/1512.03385", REAL_PDF_PAGES = "0-3", PIN_PILLOW = True, and PILLOW_VERSION = "11.3.0". Dependencies installed include reportlab, pypdfium2, pandas, matplotlib, lift-pdf[hf], bitsandbytes, and accelerate. The Pillow pinning logic prevents a known Colab compatibility issue where newer Pillow builds can break downstream
SUCKS 0
0
0
Comments
This page shows all existing comments. To add a new comment, open the post in the forum.
No comments yet.