
Developers Run Local LLMs on Windows 11
Source: letsdatascience.com
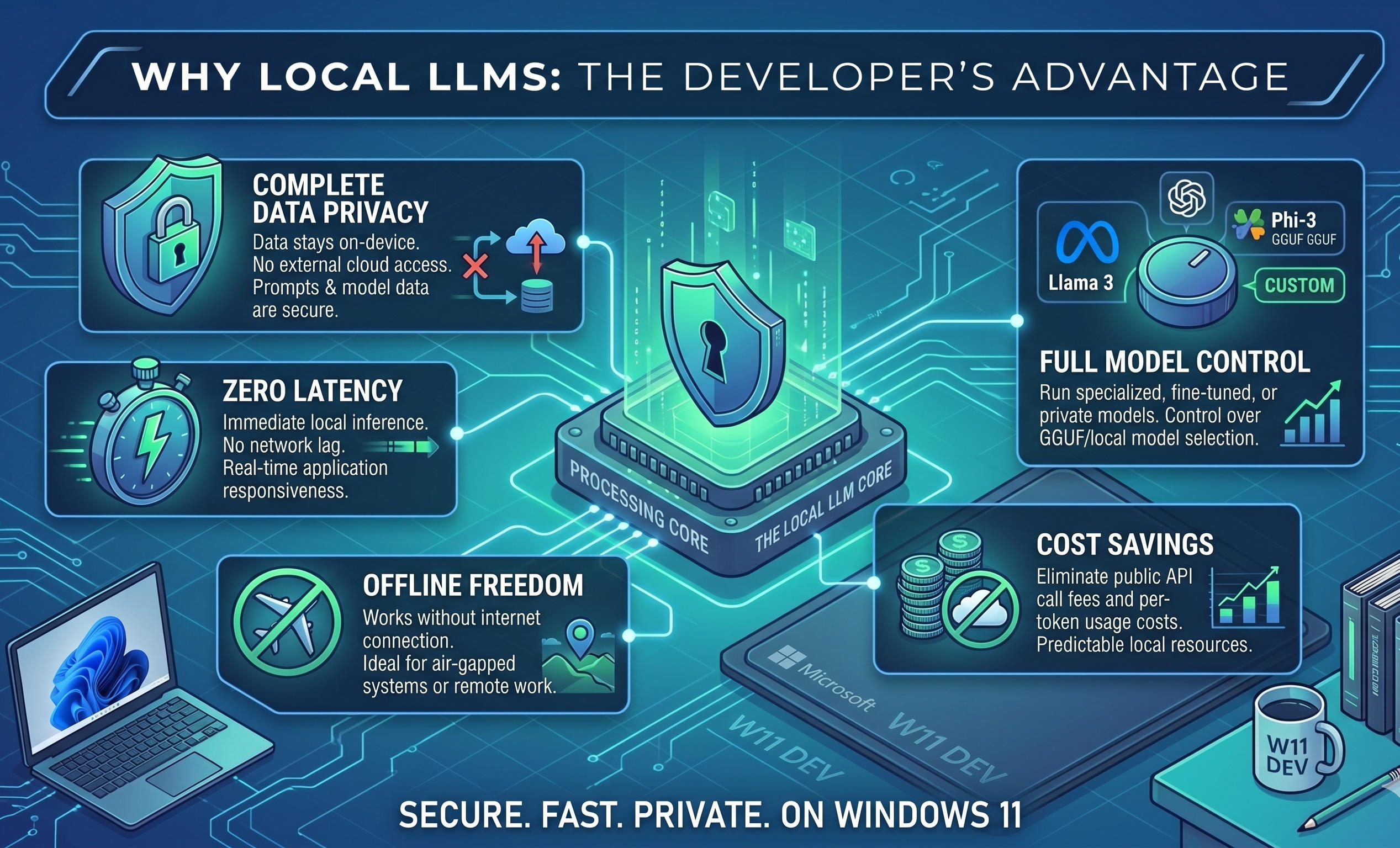
A blog post published on Blogger provides a step-by-step guide for running local large language models on Windows 11, covering models such as `Llama 3` and `Phi-3` using LM Studio and ONNX Runtime. The tutorial includes sections on hardware requirements, installing runtimes, and deployment best practices, and also discusses using Ollama and quantized model formats to reduce GPU memory needs. The author frames the workflow as privacy-first, emphasizing that keeping inference on-device avoids sending sensitive enterprise data to cloud APIs. The post recommends converting or obtaining models in ONNX-compatible formats and running inference with ONNX Runtime to take advantage of platform acceleration, and discusses quantized weights to reduce VRAM usage. The editorial analysis notes that the guide fits within a broader privacy-first trend where teams prefer on-device inference to avoid cloud data egress, and that for enterprise developers, local workflows shift effort from API integration to dependency management, driver configuration, and model optimization.
SUCKS 0
0
0
Comments
This page shows all existing comments. To add a new comment, open the post in the forum.
No comments yet.